 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOSMIC: Concurrent Optimization of Structure, Material, and Integrated Control for robotic systems
May 12, 2026Replicating and surpassing the autonomy of natural organisms remains a long-standing goal in robotics. Yet most robotic systems have their structure, materials, and control designed separately, in sharp contrast to the co-evolution in nature. This separation often leads to suboptimal designs, and we still have a limited understanding of the individual and collective contributions of these design entities. In this work, we propose a gradient-based co-design framework that simultaneously optimizes the topology, material distribution, and control policy of a truss-lattice robot. The framework embeds mixed-type topological and material variables into a continuous design space and integrates a neural network controller within a differentiable simulator, capturing their interactions and enabling efficient gradient calculation via automatic differentiation. Furthermore, we develop a constrained optimization to navigate the highly non-convex design landscape and jointly optimize all design entities. Case studies demonstrate that the proposed framework consistently discovers diverse locomotion strategies that outperform baselines obtained through separated design. The framework is also flexible to accommodate different functional requirements and boundary conditions. Using this framework, we further extract design insights that reveal the individual and collective effects of different entities on robotic performance. The proposed framework provides a computational foundation for the autonomous co-design of robotic systems, capable of reconfiguration, locomotion, and other complex autonomous behaviors.
Bringing Value Models Back: Generative Critics for Value Modeling in LLM Reinforcement Learning
Apr 12, 2026Credit assignment is a central challenge in reinforcement learning (RL). Classical actor-critic methods address this challenge through fine-grained advantage estimation based on a learned value function. However, learned value models are often avoided in modern large language model (LLM) RL because conventional discriminative critics are difficult to train reliably. We revisit value modeling and argue that this difficulty is partly due to limited expressiveness. In particular, representation complexity theory suggests that value functions can be hard to approximate under the one-shot prediction paradigm used by existing value models, and our scaling experiments show that such critics do not improve reliably with scale. Motivated by this observation, we propose Generative Actor-Critic (GenAC), which replaces one-shot scalar value prediction with a generative critic that performs chain-of-thought reasoning before producing a value estimate. We further introduce In-Context Conditioning, which helps the critic remain calibrated to the current actor throughout training. GenAC improves value approximation, ranking reliability, and out-of-distribution generalization, and these gains translate into stronger downstream RL performance than both value-based and value-free baselines. Overall, our results suggest that stronger value modeling is a promising direction for improving credit assignment in LLM reinforcement learning.
Understanding vs. Generation: Navigating Optimization Dilemma in Multimodal Models
Feb 17, 2026Current research in multimodal models faces a key challenge where enhancing generative capabilities often comes at the expense of understanding, and vice versa. We analyzed this trade-off and identify the primary cause might be the potential conflict between generation and understanding, which creates a competitive dynamic within the model. To address this, we propose the Reason-Reflect-Refine (R3) framework. This innovative algorithm re-frames the single-step generation task into a multi-step process of "generate-understand-regenerate". By explicitly leveraging the model's understanding capability during generation, we successfully mitigate the optimization dilemma, achieved stronger generation results and improved understanding ability which are related to the generation process. This offers valuable insights for designing next-generation unified multimodal models. Code is available at https://github.com/sen-ye/R3.
Muon in Associative Memory Learning: Training Dynamics and Scaling Laws
Feb 05, 2026Muon updates matrix parameters via the matrix sign of the gradient and has shown strong empirical gains, yet its dynamics and scaling behavior remain unclear in theory. We study Muon in a linear associative memory model with softmax retrieval and a hierarchical frequency spectrum over query-answer pairs, with and without label noise. In this setting, we show that Gradient Descent (GD) learns frequency components at highly imbalanced rates, leading to slow convergence bottlenecked by low-frequency components. In contrast, the Muon optimizer mitigates this imbalance, leading to faster and more uniform progress. Specifically, in the noiseless case, Muon achieves an exponential speedup over GD; in the noisy case with a power-decay frequency spectrum, we derive Muon's optimization scaling law and demonstrate its superior scaling efficiency over GD. Furthermore, we show that Muon can be interpreted as an implicit matrix preconditioner arising from adaptive task alignment and block-symmetric gradient structure. In contrast, the preconditioner with coordinate-wise sign operator could match Muon under oracle access to unknown task representations, which is infeasible for SignGD in practice. Experiments on synthetic long-tail classification and LLaMA-style pre-training corroborate the theory.
Towards Solving the Gilbert-Pollak Conjecture via Large Language Models
Jan 29, 2026The Gilbert-Pollak Conjecture \citep{gilbert1968steiner}, also known as the Steiner Ratio Conjecture, states that for any finite point set in the Euclidean plane, the Steiner minimum tree has length at least $\sqrt{3}/2 \approx 0.866$ times that of the Euclidean minimum spanning tree (the Steiner ratio). A sequence of improvements through the 1980s culminated in a lower bound of $0.824$, with no substantial progress reported over the past three decades. Recent advances in LLMs have demonstrated strong performance on contest-level mathematical problems, yet their potential for addressing open, research-level questions remains largely unexplored. In this work, we present a novel AI system for obtaining tighter lower bounds on the Steiner ratio. Rather than directly prompting LLMs to solve the conjecture, we task them with generating rule-constrained geometric lemmas implemented as executable code. These lemmas are then used to construct a collection of specialized functions, which we call verification functions, that yield theoretically certified lower bounds of the Steiner ratio. Through progressive lemma refinement driven by reflection, the system establishes a new certified lower bound of 0.8559 for the Steiner ratio. The entire research effort involves only thousands of LLM calls, demonstrating the strong potential of LLM-based systems for advanced mathematical research.
Efficient-VLN: A Training-Efficient Vision-Language Navigation Model
Dec 11, 2025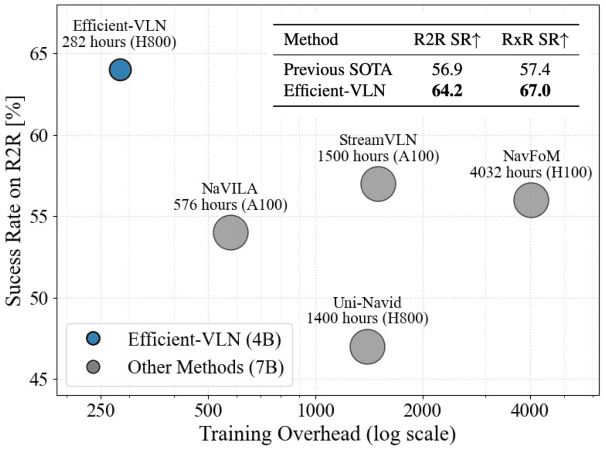
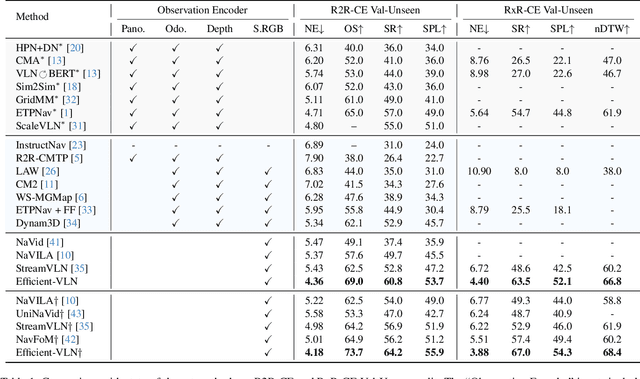
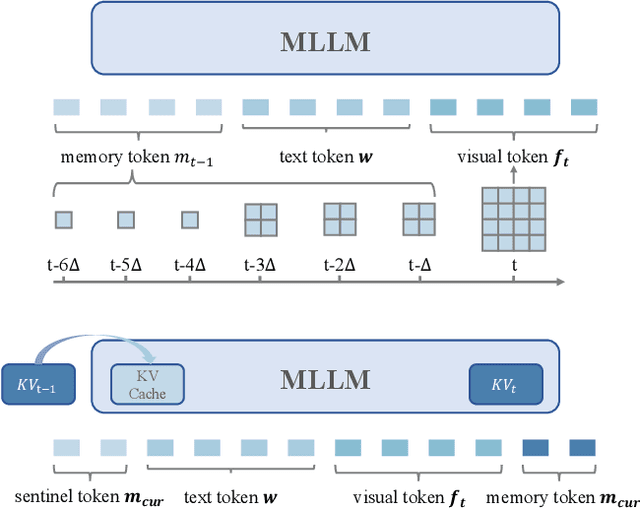
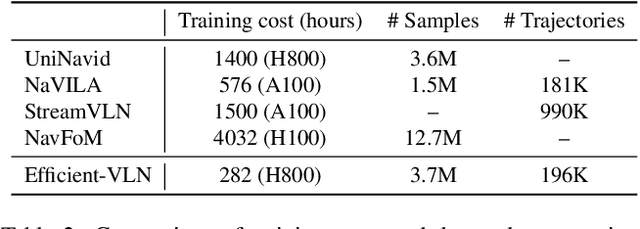
Multimodal large language models (MLLMs) have shown promising potential in Vision-Language Navigation (VLN). However, their practical development is severely hindered by the substantial training overhead. We recognize two key issues that contribute to the overhead: (1) the quadratic computational burden from processing long-horizon historical observations as massive sequences of tokens, and (2) the exploration-efficiency trade-off in DAgger, i.e., a data aggregation process of collecting agent-explored trajectories. While more exploration yields effective error-recovery trajectories for handling test-time distribution shifts, it comes at the cost of longer trajectory lengths for both training and inference. To address these challenges, we propose Efficient-VLN, a training-efficient VLN model. Specifically, to mitigate the token processing burden, we design two efficient memory mechanisms: a progressive memory that dynamically allocates more tokens to recent observations, and a learnable recursive memory that utilizes the key-value cache of learnable tokens as the memory state. Moreover, we introduce a dynamic mixed policy to balance the exploration-efficiency trade-off. Extensive experiments show that Efficient-VLN achieves state-of-the-art performance on R2R-CE (64.2% SR) and RxR-CE (67.0% SR). Critically, our model consumes merely 282 H800 GPU hours, demonstrating a dramatic reduction in training overhead compared to state-of-the-art methods.
Rethinking Chain-of-Thought Reasoning for Videos
Dec 10, 2025Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at https://github.com/LaVi-Lab/Rethink_CoT_Video.
Distribution Matching Variational AutoEncoder
Dec 08, 2025Most visual generative models compress images into a latent space before applying diffusion or autoregressive modelling. Yet, existing approaches such as VAEs and foundation model aligned encoders implicitly constrain the latent space without explicitly shaping its distribution, making it unclear which types of distributions are optimal for modeling. We introduce \textbf{Distribution-Matching VAE} (\textbf{DMVAE}), which explicitly aligns the encoder's latent distribution with an arbitrary reference distribution via a distribution matching constraint. This generalizes beyond the Gaussian prior of conventional VAEs, enabling alignment with distributions derived from self-supervised features, diffusion noise, or other prior distributions. With DMVAE, we can systematically investigate which latent distributions are more conducive to modeling, and we find that SSL-derived distributions provide an excellent balance between reconstruction fidelity and modeling efficiency, reaching gFID equals 3.2 on ImageNet with only 64 training epochs. Our results suggest that choosing a suitable latent distribution structure (achieved via distribution-level alignment), rather than relying on fixed priors, is key to bridging the gap between easy-to-model latents and high-fidelity image synthesis. Code is avaliable at https://github.com/sen-ye/dmvae.
Hierarchical Federated Learning for Social Network with Mobility
Sep 18, 2025Federated Learning (FL) offers a decentralized solution that allows collaborative local model training and global aggregation, thereby protecting data privacy. In conventional FL frameworks, data privacy is typically preserved under the assumption that local data remains absolutely private, whereas the mobility of clients is frequently neglected in explicit modeling. In this paper, we propose a hierarchical federated learning framework based on the social network with mobility namely HFL-SNM that considers both data sharing among clients and their mobility patterns. Under the constraints of limited resources, we formulate a joint optimization problem of resource allocation and client scheduling, which objective is to minimize the energy consumption of clients during the FL process. In social network, we introduce the concepts of Effective Data Coverage Rate and Redundant Data Coverage Rate. We analyze the impact of effective data and redundant data on the model performance through preliminary experiments. We decouple the optimization problem into multiple sub-problems, analyze them based on preliminary experimental results, and propose Dynamic Optimization in Social Network with Mobility (DO-SNM) algorithm. Experimental results demonstrate that our algorithm achieves superior model performance while significantly reducing energy consumption, compared to traditional baseline algorithms.
Solving the Hubbard model with Neural Quantum States
Jul 03, 2025The rapid development of neural quantum states (NQS) has established it as a promising framework for studying quantum many-body systems. In this work, by leveraging the cutting-edge transformer-based architectures and developing highly efficient optimization algorithms, we achieve the state-of-the-art results for the doped two-dimensional (2D) Hubbard model, arguably the minimum model for high-Tc superconductivity. Interestingly, we find different attention heads in the NQS ansatz can directly encode correlations at different scales, making it capable of capturing long-range correlations and entanglements in strongly correlated systems. With these advances, we establish the half-filled stripe in the ground state of 2D Hubbard model with the next nearest neighboring hoppings, consistent with experimental observations in cuprates. Our work establishes NQS as a powerful tool for solving challenging many-fermions systems.